Introduction
随着机器学习模型的规模指数级增长,高性能GPU供不应求。传统的分布式训练框架(e.g., NVIDIA的Megatron-LM和DeepSpeed)都是针对同构GPU且节点间带宽均匀的情况,然而现代数据中心可能包含多种GPU且分布在不同的区域。这种动态、异构且跨地域集群对分布式训练提出了三大核心挑战:
- 配置空间搜索复杂度高 异构GPU类型和跨区域部署使得资源分配和并行策略的组合空间呈指数级别增长。现有的策略要么无法适应这种条件,要么搜索效率低下。
- 迭代时间和内存占用的准确模拟困难 不同GPU类型和网络带宽差异增加了模拟复杂度。
- 训练框架对于异构并行和弹性的支持不足 现有框架无法支持异构集群下的配置,且资源动态变化要求框架能够快速配置作业,而现有系统缺乏高效的容错与弹性设计。
Method
Sailor系统整体包括四个核心组件。
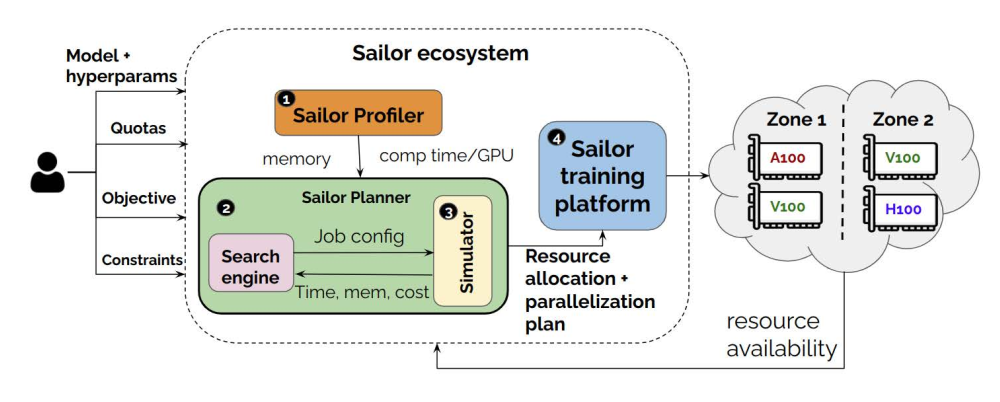
- 分析器Profiler 负责任务分析,在每种GPU类型上分析模型的每层计算时间、内存占用等;对于集群分析,测量不同节点之间的网络带宽,建立带宽与消息大小的多项式模型
- 规划器Planner
基于分析器提供的信息+吞吐量/成本目标+用户约束,联合优化资源分配与并行策略(数据并行、张量并行、流水线并行)。
该组件采用了以下技术来进行搜索优化:
- 启发式剪枝:将张量并行限制在一个节点内;预先排除OOM的配置;根据目标调整数据并行;将数据并行限制在一个region中以避免通信带来的性能损失损失等
- 动态规划:通过采用dp方法将阶段资源配置问题分解为子问题,从而重用中间结果。
- 成本约束处理:通过迭代的方式,不断调整假设的瓶颈阶段,从而近似分配预算。
- 模拟器Simulator
- 内存估计: 考虑模型参数,激活值,optimizer状态等全部内存来源,按GPU类型和并行度来计算每个阶段的内存占用
- 迭代时间估计:基于1F1B的流水线模型,结合实际的网络带宽和异构GPU计算差异来预估通信同步的迭代时间
- 成本估计:计算每个迭代的资源配置成本和跨区域通信成本
- 分布式训练框架Distributed Training Framework
- 基于Megatron-DeepSpeed进行拓展,支持异构并行,为流水线的每个阶段提供不同张量并行度
- 提供容错和弹性支持,每个job由一个控制器controller和复数workers组成,控制器负责监控资源变化,激活规划器来生成新的策略,workers重建通信组并清理显存,无需杀死现有进程,可以从最近检查点开始训练。