Introduction
Background
GPU集群上运行的大模型对于资源的利用率十分不平衡,来自用户的请求模式难以预测,绝大部分的模型只会接收极少数的推理请求,资源浪费严重,17.7%的GPU资源只被用于服务1.35%的请求。而热门的模型则会承受超过其预留资源容量的突发流量的请求。
Existing Methods & Limitations
为了让每个GPU能够更高效率地处理多个模型的请求,通常是采取GPU池化的策略。将GPU的资源集中在一起,再根据请求去动态地分配给不同的工作负载。通常的方法包括多路复用(Multiplexing)和自动扩缩容(Auto-Scaling)。
多路复用Multiplexing是比较常见的GPU划分方法,将一块物理GPU划分为多个隔离分区,然后每个分区上挂载一个模型负载。具体来分,可以分为空间多路复用和时间多路复用。空间多路复用就是像MIG、MPS这些技术,将显存划分成多个分区然后分配给用户提交的工作负;时间多路复用则是采用轮询时间片的方式,通过快速切换负载来实现并发。
这种技术的优势就是低延迟切换(模型已在显存中,不需要加载开销),能够实现较好的资源隔离且易实现。但相应的,本身硬件资源具有硬性限制(一张80GB的GPU上最多能同时安置2-3个模型),容易产生碎片化问题,缺乏弹性(无法处理请求处理过程中的动态资源需求变化)。
自动扩缩容Auto-Scaling采用的是动态装卸载的方式,GPU在同一时间只运行一个模型,当收到某个模型的请求时,将该模型挂载到GPU上运行,请求完成后,将其卸载到主机内存上再将其他模型挂载到显存。但这样就存在一个粒度问题,这种切换是在请求级别的粒度进行的,会出现队头阻塞。
时间轴: 0s--------10s--------20s--------30s--------40s
GPU: [模型A请求1=============] [模型B请求2==========]
↑ ↑ ↑ ↑
请求1开始 请求1结束 请求2开始 请求2结束
为了弥补Auto-Scaling技术在处理粒度上的不足,本文提出了Token级别的Auto-Scaling技术——Aegaeon,在token粒度上进行评估,抢占性将正在运行的模型卸载并将新请求到达的模型挂载,满足SLO(Service-Level Object)指标的同时,使得每张GPU上可挂载的模型数量大大增加。
关于SLO……
SLO 的全称是 Service-Level Objective(服务等级目标)。
可以把它理解为一个量化的、可测量的服务质量承诺。在云计算和在线服务领域,SLO 是定义用户期望服务达到何种性能水平的正式指标。与传统的一次性请求-响应服务不同,LLM 推理是一个流式生成的过程,用户体验由多个关键节点上的延迟共同决定。因此,不能简单地用整个请求的“总完成时间”来衡量好坏。在 Aegaeon 和现代 LLM 服务系统中,通常关注两个核心的、按 Token 划分的 SLO:
-
TTFT - Time To First Token
-
定义:从用户发送请求到收到第一个输出 Token 所经过的时间。
-
影响:这直接决定了用户的上手体验,一个过长的 TTFT 会让用户感觉系统“卡住了”或没有响应。
-
典型值:在交互式应用中(如聊天机器人),通常要求 TTFT < 1-2 秒。
-
-
TBT - Time Between Tokens
-
定义:在流式输出中,后续每个 Token 之间的生成时间间隔。
-
影响:这决定了输出内容的流畅度。一个稳定且较低的 TBT 会让输出像“打字”一样流畅出现。如果 TBT 过高且波动大,输出会变得一卡一卡的,体验很差。
-
典型值:对于流畅的对话,TBT 通常需要 < 100-200 毫秒。
-
文中第2.1节的最后给出了SLO attainment的定义,即“满足其截止时间的Token的生成次数的百分比”。
Overview of Aegaeon
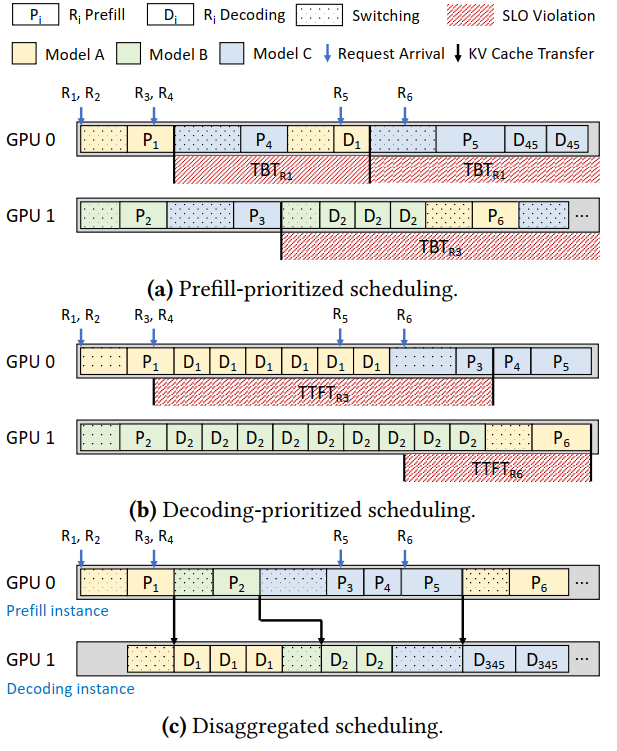
本文的一个关键问题是如何实现Token-Level Scheduling。首先是Unified Scheduling Policies,包括Prefill-prioritized和Decode-prioritized,这两种调度方案都是将对应请求的Prefill和Decode阶段都放在同一GPU上进行,但其缺点就如图上所示,前者会导致TBT不满足SLO需求(请求生成内容不流畅)而后者则是TTFT不满足SLO需求(请求回应的等待时间过长)。为此,需要采用(c)中所示的将Prefill和Decode阶段分离到两张卡上进行的Disaggregated Scheduling Policy。
Prefill-Phase Scheduling
在Prefill阶段采取的策略是分组FCFS,核心是在保证整体上FCFS的前提下,将同一模型的请求批量化处理以减少模型切换的成本。
数据结构实现:
- 每个 Prefill 实例维护一个作业队列。
- 队列中的元素不是单个请求,而是组。每个组包含属于同一模型的多个请求。
- 组的大小有上限
MAX_GROUPSIZE(论文中设为8)。
新请求到达时:
- 步骤1(寻找现有组):调度器遍历所有 Prefill 实例的作业队列,寻找是否存在一个属于目标模型
r.model且尚未满员的组。 - 步骤2(加入或创建):
- 如果找到:将该请求
r加入这个现有的组。这是首选方案,因为它避免了创建新组可能引发的模型切换。 - 如果未找到:为请求
r创建一个新的组。然后将这个新组添加到负载最轻的 Prefill 实例的作业队列末尾。负载的计算依据是队列中所有组的预计执行总时间(包括预填充计算时间和潜在的模型切换时间)。
- 如果找到:将该请求
执行时:
- 实例从其作业队列的头部取出第一个组。
- 如果当前GPU上加载的模型不是这个组所需的模型,则执行一次模型切换。
- 然后,该组内的请求被逐个执行(批大小为1),生成它们的第一个 Token。之后,这些请求被移交到 Decode 实例。
通过将同模型请求分组,一次模型切换可以服务最多8个请求,极大地降低了每个请求平摊的切换开销。此外,虽然进行了分组,但整体仍是FCFS。新创建的组被放在队列尾部,防止后到的请求插队。设置批大小为1并限制组大小,是为了防止单个大组长时间占用实例,能让请求尽快进入解码阶段,有助于降低 TBT。
Decode-Phase Scheduling
在Decode阶段采取的策略是加权轮转调度,通过将时间切片,每个轮次中,为Active Models分配相应的配额,以轮转的方式去执行,保证所有请求都能获得进展。
数据结构实现:
- 每个 Decode 实例维护一个工作列表。
- 列表中的每个元素是一个Decode Batch,包含属于同一模型的一组请求和相应的时间配额
请求到达时:从 Prefill 阶段完成的请求会被分发到 Decode 实例,基于KV 缓存容量来确定batch size。
执行时(核心):
- a. 轮次开始:
- 重排序:将工作列表中属于同一模型的批次调整到相邻位置。这是为了在后续轮转中,连续处理同模型批次,减少不必要的模型切换。
- 计算配额:为工作列表中的每一个批次 $i$计算一个时间配额 $q_i$。
- b. 配额计算原理:
- 定义 $\large n_i = \frac{d}{t_i}$。其中 $d$ 是目标 TBT(如 100ms),$t_i$ 是批次 $i$解码一个 Token 的实际时间。$n_i$可以理解为该批次的速度,$n_i$ 越大,说明该批次解码越快,理应获得更多机会。
- 公式 $\large q_i = \frac{c}{ n_i \times (\alpha - \sum_k(\frac{1}{n_k})) }$ ,其中$c$是工作列表中所有模型的auto scaling开销之和,该公式的目标是,让分配给每个批次的时间配额,能使得本轮次的总 SLO attainment 达到 $\frac{1}{\alpha}$。
- $\alpha$ 是一个控制参数,确保配额不会无限大($\alpha \ge 0.5$),它代表了系统在满足 SLO 和实现多路复用之间的权衡。
- c. 轮转执行:
- 实例按照工作列表的顺序,执行每个批次。
- 对于批次 $i$,它连续解码其请求,持续时间精确为 $q_i$
- 时间配额用完后,实例立即切换到下一个批次。
- 一个轮次结束后,开启新一轮次,重新计算配额并继续。
通过这一设计,每个请求所在的批次在每个轮次都能获得执行时间,确保所有请求都有进展,不会饥饿。通过短暂的、受控的停顿去服务其他请求,系统巧妙地利用了用户阅读时间作为缓冲。只要整个轮次的总时间不至于导致输出中断,用户体验就是流畅的。同时,配额公式直接与 TBT 目标 $d$ 挂钩,使得调度决策是 SLO-aware 的。系统会自动为解码速度快的请求分配更多资源,从而在整体上最大化 SLO 达成率。
Efficient Preemptive Auto-Scaling
在确定了调度策略之后,一个关键的问题就是如何实现高效的抢占调度操作。对于正常情况下的模型切换主要包含下图的阶段
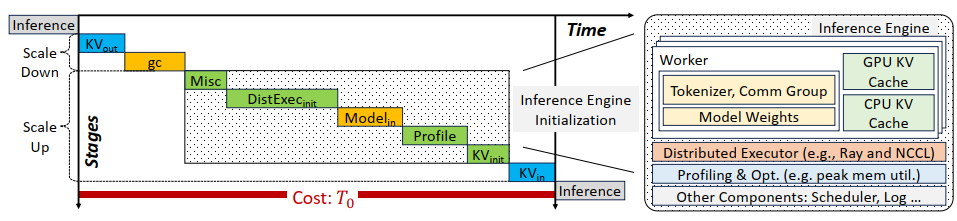
- 旧实例保存KV Cache卸载到主机内存
- 传输Garbage Collection
- 重新初始化新的实例
- 加载新实例的KV Cache
- 开始推理
Aegaeon的优化主要集中在三方面
- 初始化分解与成分重用
- 显式内存管理
- 细粒度KV Cache同步
一、初始化分解与成分重用
当从一个模型(Model A)切换到另一个模型(Model B)时,传统的推理引擎(如 vLLM)需要执行一个上述完整的切换流程,时间开销十分巨大。Aegaeon发现,推理引擎的许多组件是模型无关的,其初始化开销可以在多次模型切换中被摊销,因此设计提出了组件重用。
具体做法:
- 一次性初始化:在每个 GPU 实例启动时,Aegaeon 就完成所有模型无关组件的初始化,包括分布式执行器、性能剖析结果、调度器、tokenizer 等,并将它们缓存起来。
- 模型特定数据动态切换:在自动扩展时,只动态替换模型特定的部分,即模型权重和KV Cache
- 预分配内存池:预先分配好用于存储 KV Cache 的主机内存池,避免了每次缩放时临时锁定内存页的开销。
二、显式内存管理
在频繁的模型加载/卸载过程中,传统的张量库(如 PyTorch)内存分配器会产生严重的内存碎片化,无论是在 GPU 显存还是主机内存中。
- GPU 显存碎片:导致即使总空闲内存足够,也无法成功分配一块连续的较大内存给新模型,从而触发耗时的垃圾回收和整理操作。
- 主机内存碎片:影响模型权重的缓存效率(因为需要连续空间来存放大模型文件)。不同模型的 KV Cache 形状不同,如果为每种形状预分配固定块,会造成巨大浪费;如果动态分配,则会产生碎片。
Aegaeon采用统一管理的方式来处理VRAM和DRAM的碎片化问题。
-
自管理的 VRAM 缓冲区:
- 启动时,一次性向系统申请绝大部分所需的 GPU 显存,形成一个大的、连续的内存池。
- 在这个池内使用 指针递增分配。分配时简单地移动指针;释放时(模型切换后)可以直接将指针重置到起始位置,实现瞬时释放。
- 通过“Monkey-Patch”技术,让模型权重的分配指向这个自管理缓冲区,绕过了 PyTorch 默认的分配器,从而避免出发Garbage Collection。
-
快速模型加载:
- Model Cache:在主机内存中维护一个共享区域,缓存所有模型的原始权重张量块。
- Stage Buffer:为每个 GPU 分配一个页锁定的主机内存缓冲区,专门用于在主机和 GPU 之间采用多线程+分块+流水线的方式传输模型权重数据,最大化 PCIe 带宽利用率。
- 预取:在VRAM容量充足时,根据调度器的决策,提前在后台将下一个可能需要用到的模型权重加载到 GPU 显存中空闲的区域。当实际需要切换时,只需在 GPU 内部进行一次快速的数据拷贝即可,实现了近瞬时的模型加载。
-
统一的 KV Cache(Slab 分配):
为了解决不同形状 KV Cache 的存储问题,Aegaeon 在主机和 GPU 内存中都采用了 Slab 分配器。通过将内存分块为 Slab,每个 Slab 被分配给一种特定的 KV Cache 形状。当需要为某个形状的 KV Cache 分配空间时,就从对应的 Slab 中取一个空闲块。释放时,将块归还给对应的 Slab。
三、细粒度KV Cache同步
在抢占式扩展中,KV Cache 需要在 GPU 和主机内存之间 swap in/out。为了降低延迟,一般使用多个 CUDA 流来重叠执行这些传输操作与其他计算。然而,这里存在复杂的依赖关系:
- Decode操作必须等待其对应的 KV Cache 完全换入后才能开始。
- 只有当Prefill intance完成换出,换入操作才能开始
- 选择换出的CPU缓存时,不能选择那些正在进行传输的部分。
如果简单地异步执行,会引发数据竞争,导致推理结果错误。传统的粗粒度同步(如阻塞整个流)又会丧失并发性。
Aegaeon采用 CUDA events 来单个单个地追踪传输的状态。当针对请求构建KV Cache的传输时,Aegaeon通过cudaEventRecord来将其记录为一个事件,后续可以使用cudaEventQuery来查询这一传输的状态或者等待此传输的完成cudaStreamWaitEvent,事件也可以通过IPC在实例之间进行传递以进行同步。
重叠KV Cache换入
- Decode实例在换入 KV Cache 前,通过
cudaStreamWaitEvent命令,让它的“换入流”等待prefill实例的“换出 Event”。 - 在批量解码时,Aegaeon 会查询每个请求的 KV Cache 换入状态,只要有一个请求准备就绪,就可以立即开始解码,而不必等待整个批次。
重叠KV cache换出
换出操作被完全解耦到后台异步执行。引入 Move List 来追踪那些正在被换出到主机的内存块。当分配新的主机内存块时,会避开移动列表中的块,从而自动遵守依赖关系。一个后台daemon线程会定期查询这些换出操作的 Event,换出完成后将对应的块从移动列表中移除,使其可用。